
After determining our project, our aim this week was to examine other studies on this subject and make notes for ourselves from these studies.
In this context, we examined 3-4 studies we found, the links of which can be found below.
1-) “Multi-Label Clothing Recommendation with Deep Learning” by Seong Joon Yoo and Youngsuk Kim (2016)
• Resource: https://ieeexplore.ieee.org/document/9869006
2-)”Fashion Recommendation with Deep Bidirectional LSTM and Attention Mechanism” by Sunghun Kang et al. (2019)
• Resource: https://arxiv.org/abs/1708.07347
3-)”A Capsule-Based Multi-Label Fashion Recommendation System” by Chen et al. (2020)
• Resource: https://ieeexplore.ieee.org/document/9707459
4-)”Fashion Recommendation via Cross-Attention Networks” by Shuai Yang et al. (2020)
• Resource: https://arxiv.org/abs/1908.10585
In these studies we examined, we noticed the differences in CNN model selection, and examining these projects gave us a different perspective before choosing the CNN model we will do in the coming weeks.
We also noticed the ‘RESNET50’ and ‘VGG16’ CNN models, which are the most preferred in these projects, and we did research for these two models.
Resnet50:
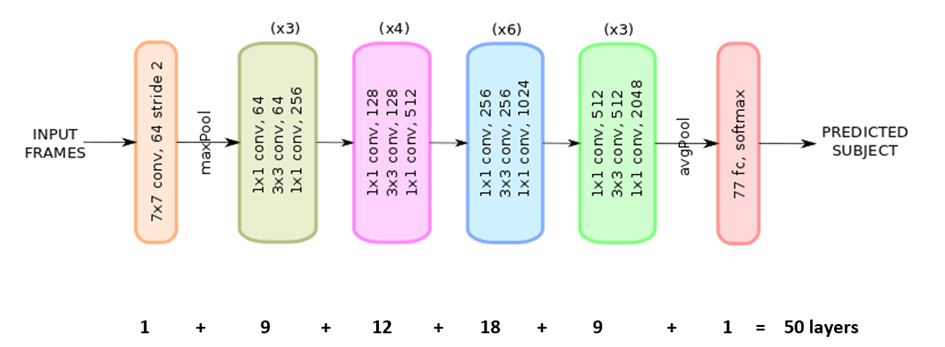
The 50-layer ResNet architecture includes the following elements, as shown in below:
- A 7×7 kernel convolution alongside 64 other kernels with a 2-sized stride.
- A max pooling layer with a 2-sized stride.
- 9 more layers—3×3,64 kernel convolution, another with 1×1,64 kernels, and a third with 1×1,256 kernels. These 3 layers are repeated 3 times.
- 12 more layers with 1×1,128 kernels, 3×3,128 kernels, and 1×1,512 kernels, iterated 4 times.
- 18 more layers with 1×1,256 cores, and 2 cores 3×3,256 and 1×1,1024, iterated 6 times.
- 9 more layers with 1×1,512 cores, 3×3,512 cores, and 1×1,2048 cores iterated 3 times.
- Average pooling, followed by a fully connected layer with 1000 nodes, using the softmax activation function.
VGG16:

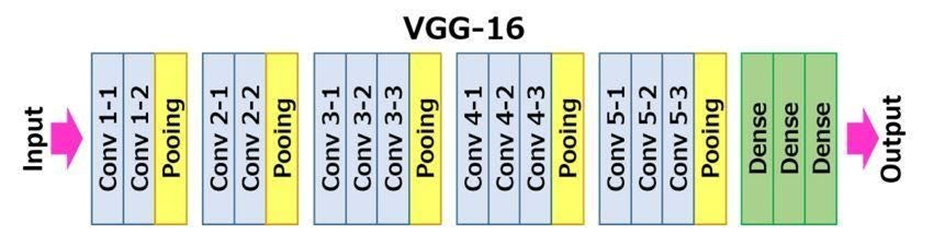
VGG16 architecture:
- Input:
VGGNet receives a 224×224 image input. In the ImageNet competition, the model’s creators kept the image input size constant by cropping a 224×224 section from the center of each image.
- Convolutional layers:
The convolutional filters of VGG use the smallest possible receptive field of 3×3. VGG also uses a 1×1 convolution filter as the input’s linear transformation.
- Hidden layers:
All the VGG network’s hidden layers use ReLU instead of Local Response Normalization like AlexNet. The latter increases training time and memory consumption with little improvement to overall accuracy.
- Pooling layers:
A pooling layer follows several convolutional layers—this helps reduce the dimensionality and the number of parameters of the feature maps created by each convolution step. Pooling is crucial given the rapid growth of the number of available filters from 64 to 128, 256, and eventually 512 in the final layers.
- Fully connected layers:
VGGNet includes three fully connected layers. The first two layers each have 4096 channels, and the third layer has 1000 channels, one for every class.